
티스토리 뷰
반응형
상장 법인 목록에 있는 모든 법인에 대한 일별시세를 크롤링하려고 합니다.
참고로 상장 법인 목록은 아래 링크를 통해 확인할 수 있습니다.
http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13
먼저 결과부터 보여드릴게요.

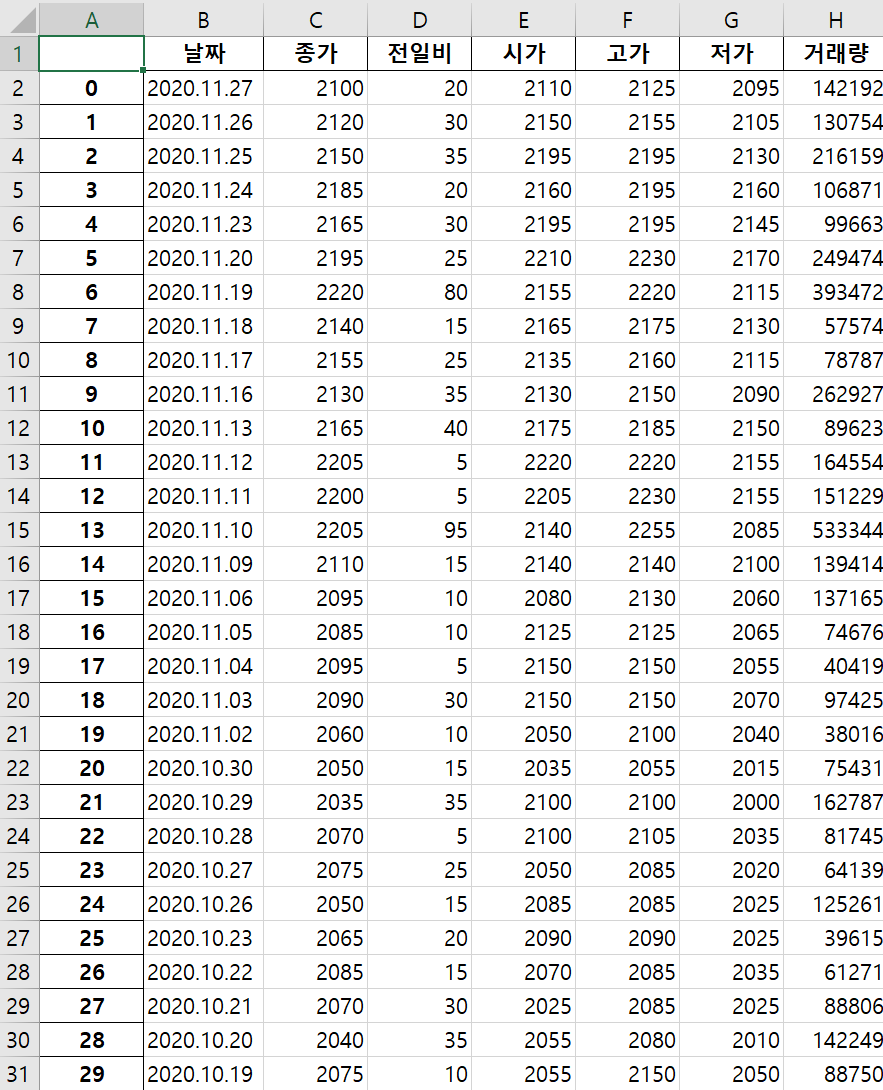
법인 총 2394개에 대한 일별 시세를 모두 가져왔습니다!!
수가 많다보니 날짜, 종가, 전일비, 시가, 고가, 저가, 거래량만 저장했음에도 300mb가 넘어가네요.
그럼 코드를 천천히 설명해 보겠습니다.
if __name__ == "__main__":
dataset_path = '일별시세'
if not os.path.exists(dataset_path):
os.makedirs(dataset_path)
code_df = pd.read_html('http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13', header=0)[0]
code_df.종목코드 = code_df.종목코드.map('{:06d}'.format)
# 회사명, 종목코드를 제외하고 나머지 column 제외
code_df = code_df[['회사명', '종목코드']]
code_df = code_df.rename(columns={'회사명': 'company', '종목코드': 'code'})
# print(code_df.head())
for row in code_df.itertuples():
print(row.company)
mainUrl = 'http://finance.naver.com/item/sise_day.nhn?code={code}'.format(code=row.code)
mainUrl = '{mainUrl}&page={page}'.format(mainUrl=mainUrl, page=1)
last_page = get_last_page(mainUrl)
if os.path.isfile(os.path.join(dataset_path, '%s.xlsx' % row.company)):
append_data_to_excl(row.company, row.code)
else:
create_new_excl(row.company, row.code)코드 흐름을 설명해 보자면..
1. 일별시세 디렉토리가 있는지 확인 후 없으면 생성한다.
2. http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13 에서 법인 목록을 가져와서 dataframe에 저장한다.
3. dataframe에서 불필요한 데이터를 제거한다.
4. 모든 법인에 대해 for문을 돌면서 기존 데이터 파일이 있으면 데이터를 덧붙이고, 없으면 새로 생성한다.
음..가볍게 적을려고 했는데 한줄 한줄 설명하려니 너무 길어질 것 같네요.
전체 코드 먼저 올려두고, 시간 될 때 천천히 내용 보충하도록 할게요.
def get_last_page(url):
print("getLastPage : ", url)
source = requests.get(url).text
soup = BeautifulSoup(source, "html.parser")
result_set = soup.select("td.pgRR > a")
if len(result_set) == 0:
return '2'
last_page_url = result_set[0]['href']
print(last_page_url)
last_page = re.findall('(?<=page=)\\d*', last_page_url)
print(last_page)
return last_page[0]
def get_data_frame(code):
df = pd.DataFrame()
for page in range(1, int(last_page)):
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}'.format(code=code)
url = '{url}&page={page}'.format(url=url, page=page)
print(url)
df = df.append(pd.read_html(url, header=0)[0], ignore_index=True)
df.dropna(subset=['날짜'], inplace=True)
return df
def get_latest_data_frame(code, date):
print('get_latest_data_frame() code : %s, date : %s' % (code, date))
df = pd.DataFrame()
for page in range(1, int(last_page)):
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}'.format(code=code)
url = '{url}&page={page}'.format(url=url, page=page)
print(url)
df = df.append(pd.read_html(url, header=0)[0], ignore_index=True)
df.dropna(subset=['날짜'], inplace=True)
print('df.iloc[-1].날짜 %s' % df.iloc[-1].날짜)
if df.iloc[-1].날짜 < date:
print('@@@@@@ page : %s' % page)
break
return df
def create_new_excl(company, code):
df = get_data_frame(code)
writer = ExcelWriter(os.path.join(dataset_path, '%s.xlsx' % company))
df.to_excel(writer, '일별시세')
writer.save()
def append_data_to_excl(company, code):
old_df = pd.read_excel(os.path.join(dataset_path, '%s.xlsx' % company))
new_df = get_latest_data_frame(code, old_df.iloc[0]['날짜'])
new_df = new_df.sort_index(ascending=False)
# 최신 기준으로 엑셀에 빠진 데이터 추가
updated = False
for row in new_df.itertuples():
if row.날짜 > old_df.iloc[0]['날짜']:
old_df.loc[-1] = row
old_df.index = old_df.index + 1
old_df = old_df.sort_index()
updated = True
if updated:
writer = ExcelWriter(os.path.join(dataset_path, '%s.xlsx' % company))
old_df.drop(old_df.filter(regex="Unname"), axis=1, inplace=True)
old_df.to_excel(writer, '일별시세')
writer.save()
반응형
'개발 > 파이썬' 카테고리의 다른 글
| "ImportError: Cannot import name X" 또는 "AttributeError" 를 어떻게 해결하나요? (0) | 2022.11.25 |
|---|---|
| 다른 .py 파일에서 함수를 호출하려면 어떻게 해야 합니까? (0) | 2022.11.25 |
| Attempted relative import in non-package 문제 수정 (0) | 2022.11.25 |
| 가져오기 오류: 이름이 지정된 모듈 요청이 없습니다. (0) | 2022.11.25 |
| virtualenv에서 Python 3 사용 (0) | 2022.11.25 |
댓글
공지사항
최근에 올라온 글